AI for peer review, ft. Claude Fable
The bull case for peer review is that, when done right, it is an extremely powerful tool for vetting and improving scientific results. The bear case is that peer review is rarely done right; instead, it is a low-throughput, mixed-quality process that critically relies on highly skilled, unpaid labor. Wherever you sit on this, I think we agree that some aspects of peer review are badly broken. Furthermore, as AI-assisted science brings about a flood of new paper submissions to the legacy scientific journals, the already clogged peer review pipeline will likely burst.
The question is then: can AI tools fix peer review? To get a feel for the state of play, I ran a little experiment using frontier AI models to peer-review some of my own old papers.
What does a peer reviewer actually do?
The term “review” in “peer review” is actually a bundle of two distinct roles:
- Impact assessment. Peer reviewers form an opinion on the overall quality of the paper, and its likely impact on the field against the background literature. Based on this, they recommend to the editor whether the paper should be published in a given journal.
- Technical validation. Peer reviewers verify the analyses, poke holes in the methods, and question assumptions that went into the derivations. Based on this, they recommend to the authors how the paper can be fixed or strengthened.
In my experience, impact judgement is rarely the bottleneck - few things make us happier than to share our opinions with others. It is also the part I wouldn’t want to outsource to AI right now.
Technical verification, on the other hand, currently leaves a lot to be desired. In some platonic ideal world, an ultra-diligent peer reviewer would go through the paper claim by claim, and independently verify each one. However, given how much time that would take - especially for 99.9% of the papers where authors don’t make verification particularly easy - reviewers usually resort to “skimming”, spot-checking, and only digging into the claims that “smell funny”. This means poor probability of spotting and fixing errors, which is particularly problematic given the public perception that peer-reviewed publications are truly “verified” or “true”.
AI as ultra-diligent technical reviewer
Whatever you think of AI models, they are diligent and - when orchestrated appropriately - will keep working on the most tedious of tasks until they’re completed or you run out of tokens. Armed with this insight, I created a pipeline that emulates my platonic ideal of an ultra-diligent technical peer reviewer. The project - available on GitHub - contains the following stages:
- Ingest: agent downloads the paper, all associated supplementary information, attached code & datasets, as well as the citations. These are the complete artefacts associated with the paper
- Extract: agent reads the paper and extracts all individual claims. Claims can be analytical (“Taking the rotating wave approximation on Eq.1 we arrive at Eq. 2”), numerical, empirical (“we measure coherence time of 2 ms”), citation-based (“experiments to date struggled to reduce error rate below 1e-3 per gate”), and plots.
- Verify: agents read individual claims and attempt to verify them through any means necessary - reading background literature, doing independent derivations and numerics, re-plotting data etc. At the end, each claim gets a verification report, together with a label of “verified”, “partial”, or “not verified”. Verification can be run multiple times through different agents, allowing agents to correct each other’s work.
- Report: a report (markdown and html) is compiled summarising the verification attempts
I have run this pipeline on a couple of my own papers. Here are the results
Paper 1, ft. Claude Sonnet 4.6
For the first experiment, I picked my first first-author paper, Probing the limits of correlations in an indivisible quantum system (arXiv:1712.06494). This work was a good intro point for AI since:
- It was pretty straightforward mathematically
- It came with a dataset, so the agent could independently re-run the data analysis
For this test, I used a cheap model claude-sonnet-4.6. The first version of the review pipeline produced the following report. Let’s take a look.
First, the scorecard. Not bad!
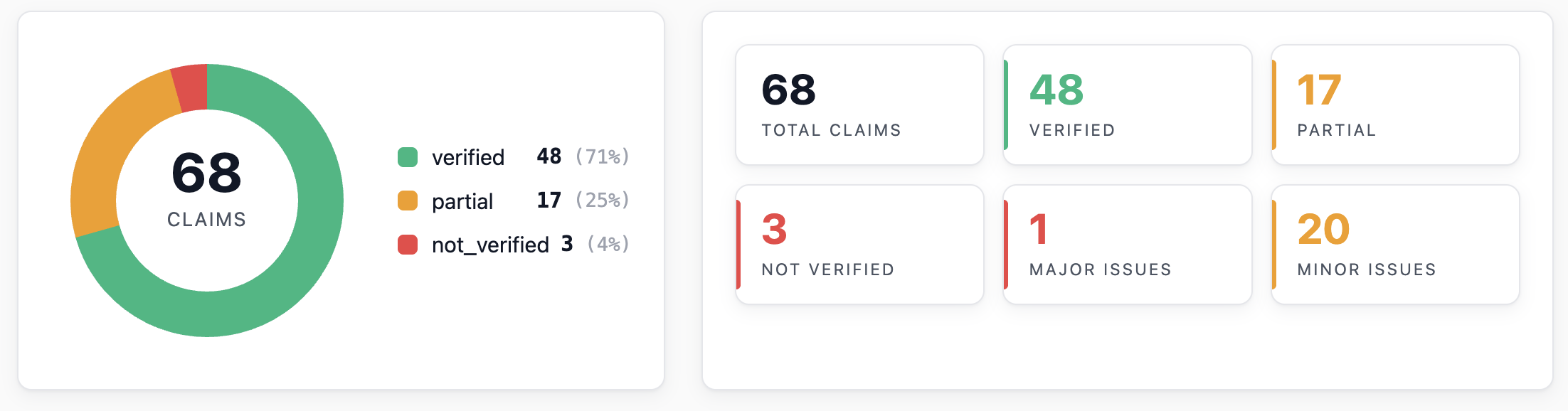
Let’s take a look at what the agent found. On analytics, it basically re-derived every mathematical claim in sympy, which is amazing.

Through this process, it found two errors in my analysis. First was a typo (pi/2 instead of pi/4). AI did a very good job making it very obvious I was wrong
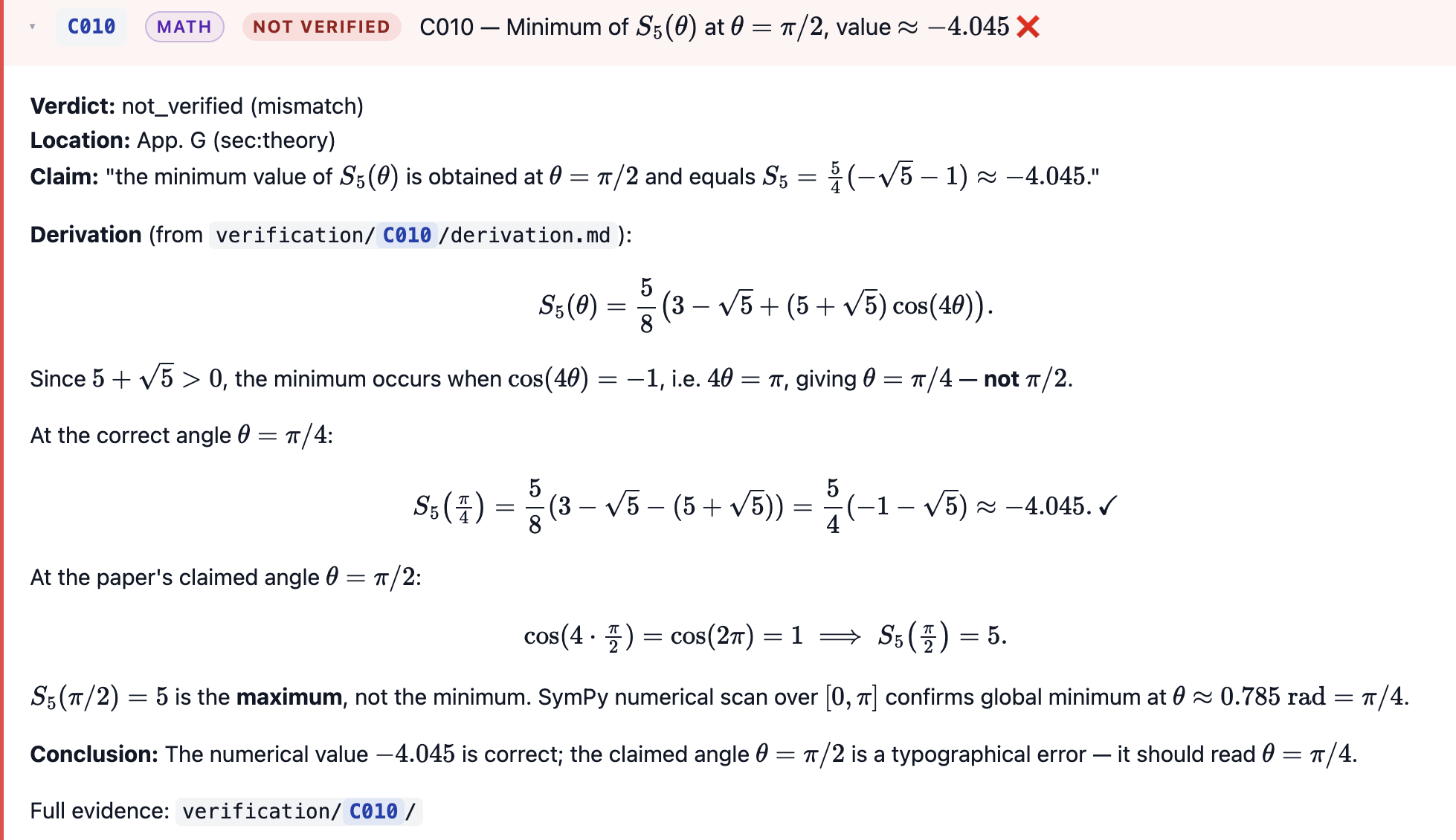
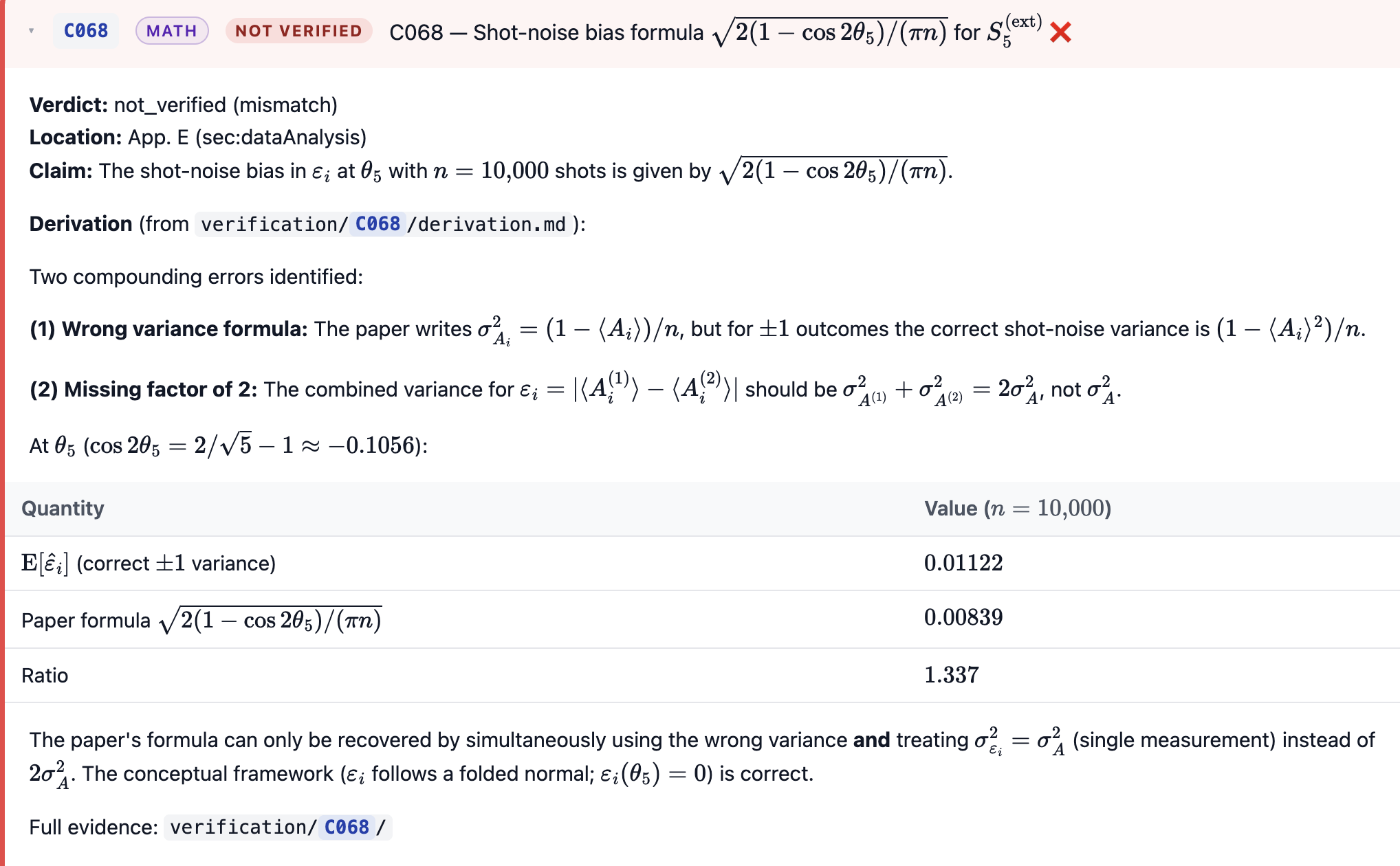
Second, an actual error in the formula I used for calculating error bars. Better than that - it showed me how I made two errors that mostly canceled out, such that the final result was a 30% underestimation of the uncertainty. This is exactly what I was hoping for - because AI has patience to go through this line-by-line, it can verify individual mathematical statements that none of my peer reviewers or collaborators ever bothered to look at.
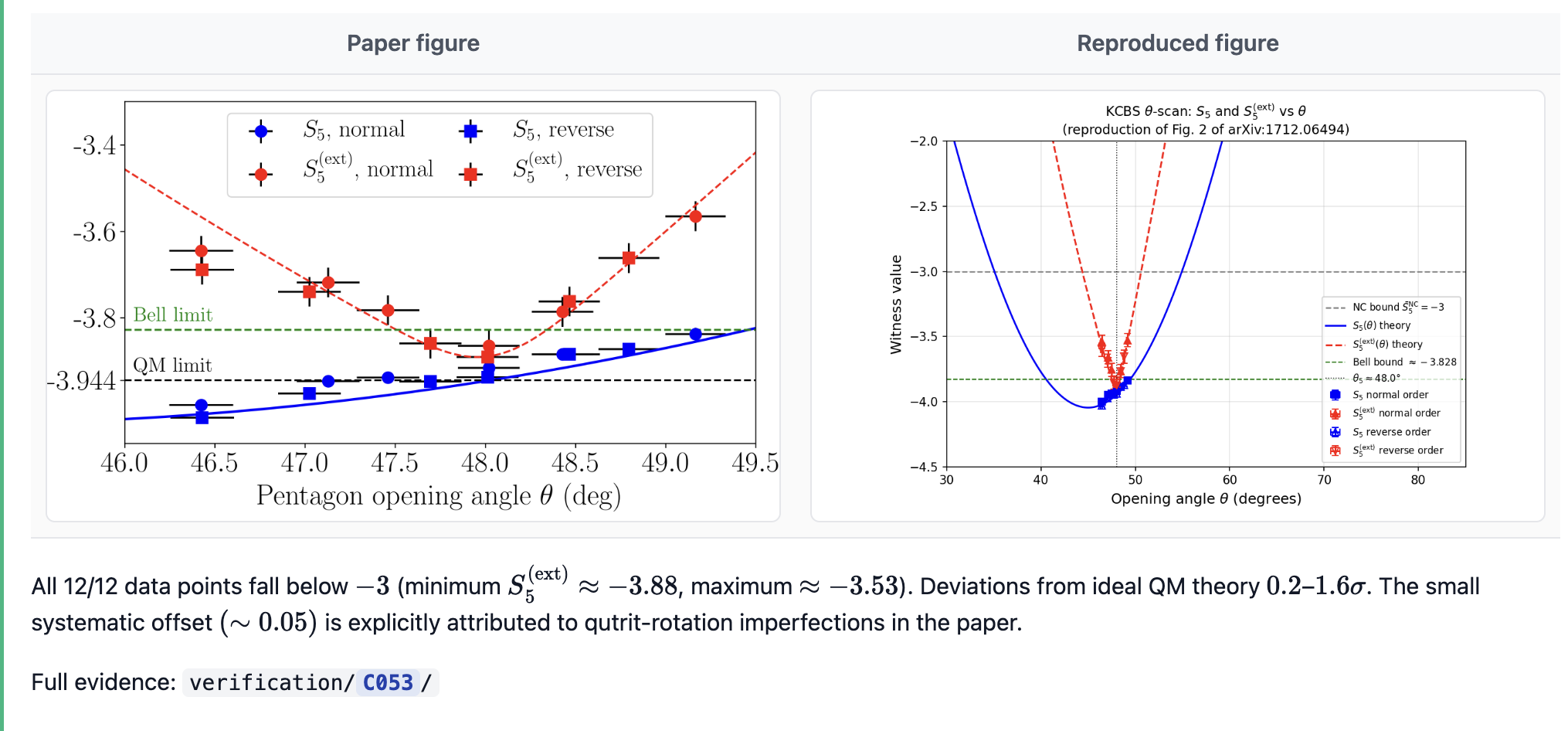
While most numerical values in the paper were unverifiable, AI did something neat and verified my numbers against a different paper on the same apparatus. It also checked for internal consistency, e.g. between the ion temperature and the Doppler limit, or the qubit frequency noise and the coherence time


When it comes to plots, AI was able to independently rerun the whole pipeline of “raw data to plot” and verify the values of all data points explicitly quoted in the paper, as well as achieve a visual match between original and reproduced figures. This was my happiest moment. To be clear - while the raw data has been available online for the past 9 years, I’m pretty sure this is the first time anyone attempted to rerun this analysis.
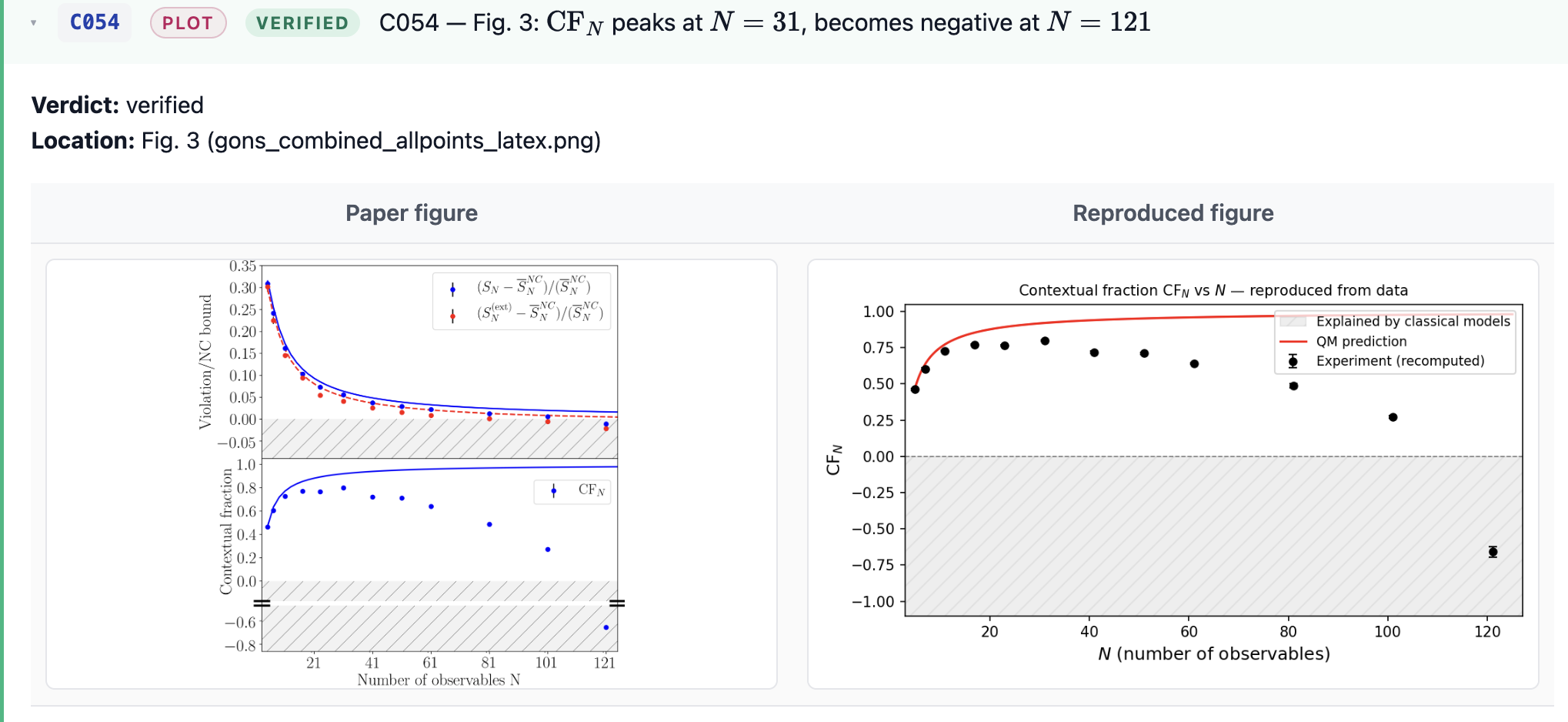
For citations, the agents verified I did not misquote anyone

and the empirical claims were independently confirmed with re-computed values, surfacing minor errors


Having gone through many rounds of peer review of this paper, I can 100% confirm this was by far the best technical peer review this paper had ever received. While human peer reviewers were strong on the overall value and impact, as well as the philosophical aspects of these tests, their technical verification was way less impactful than 30 minutes of claude-sonnet-4.6.
Paper 2, ft. Claude Opus 4.8 + GPT 5.5 xhigh
For the second experiment, I picked the final paper from my PhD, “Generation of a maximally entangled state using collective optical pumping” (arXiv:2107.10374). Because that work contained some slightly more difficult mathematics and simulations, I went with more powerful Claude Opus 4.8 + GPT 5.5 xhigh. Following earlier successful experiments with coding, I ran two passes of review, alternating between the models. You can explore the report here.
First, the score
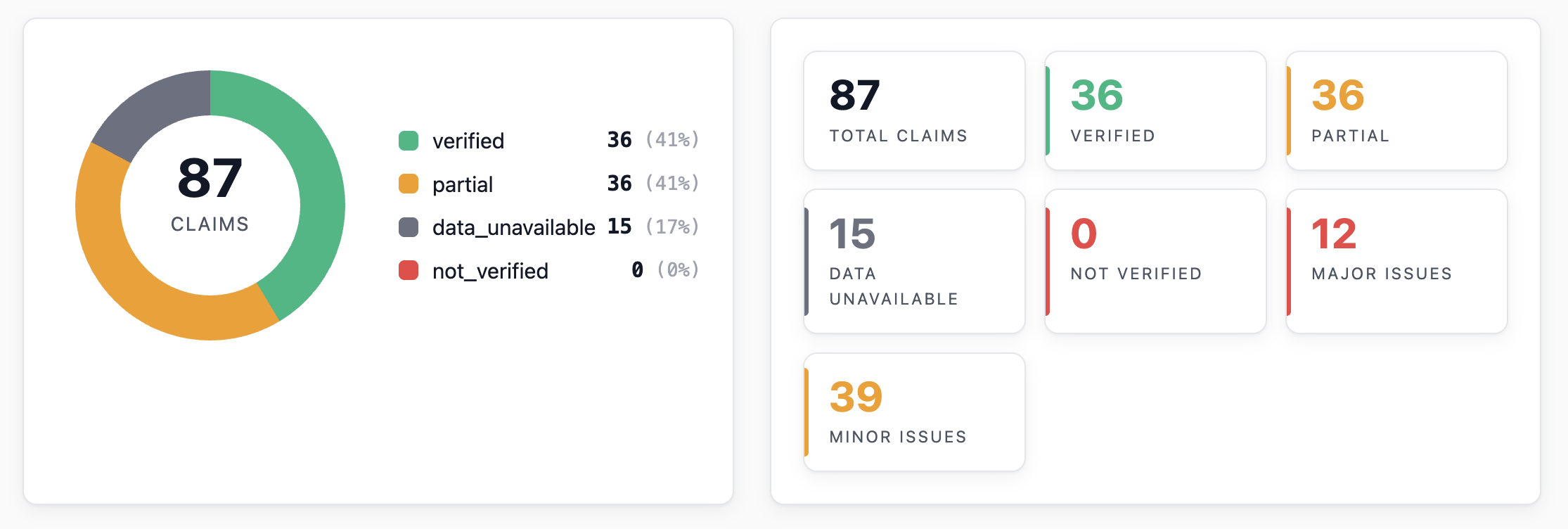
As before, the reviewer broke the paper into atomic claims. As you can see, I updated the pipeline so I can now click on each claim and see the full derivation, which is pretty neat


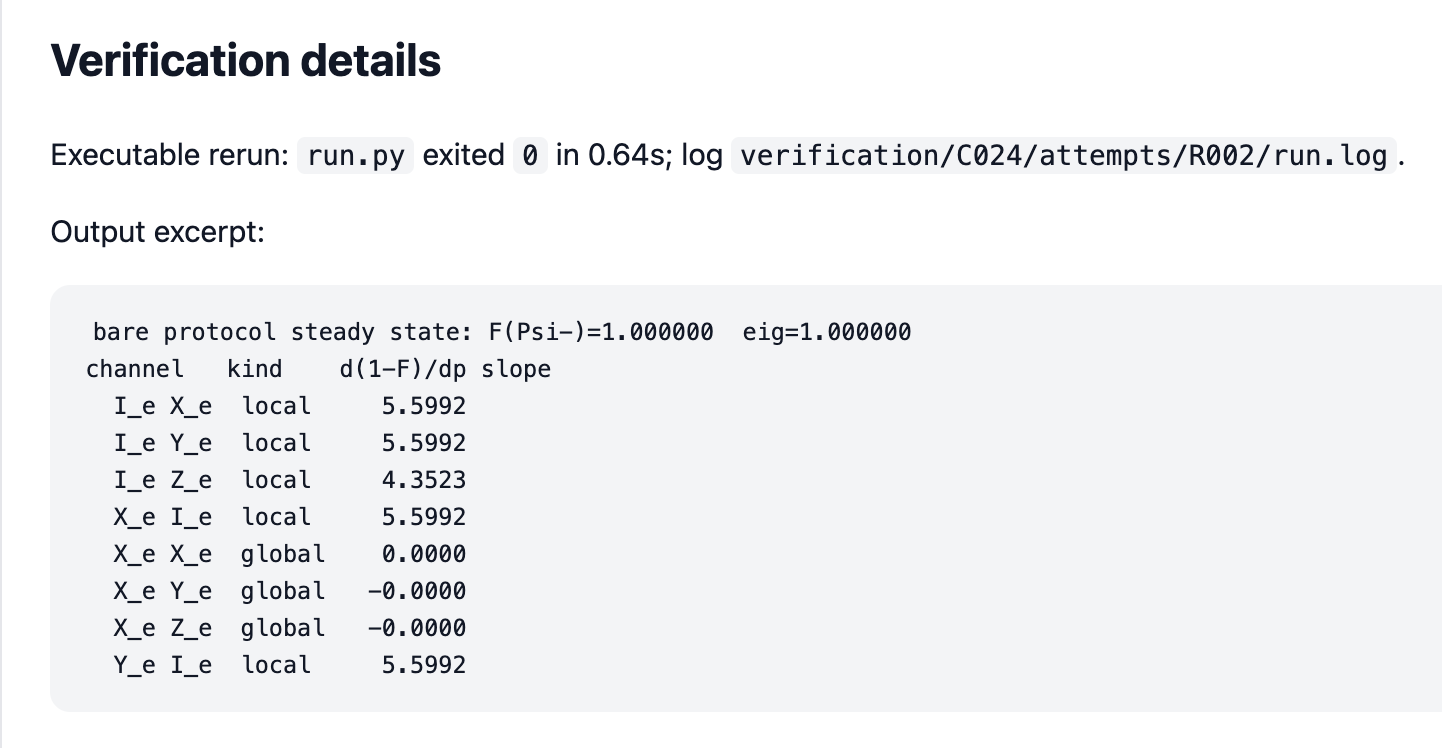
Some claims were verified analytically and numerically, but even pure numerical verification is fairly useful. For example, claim 24 says that my entangling protocol amplifies local errors but suppresses global errors - something I recall establishing analytically. The AI, on the other hand, verified this by running simulations with all possible global and local errors while scanning error probability p, and then extracting the gradient of the error with respect to p.
The question that interested me the most was whether AI would be able to reproduce my simulations of how the error in the final entangled state depends on physical error sources. This is the plot from the paper, comparing my protocol (in blue) vs standard 2Q gates (green)
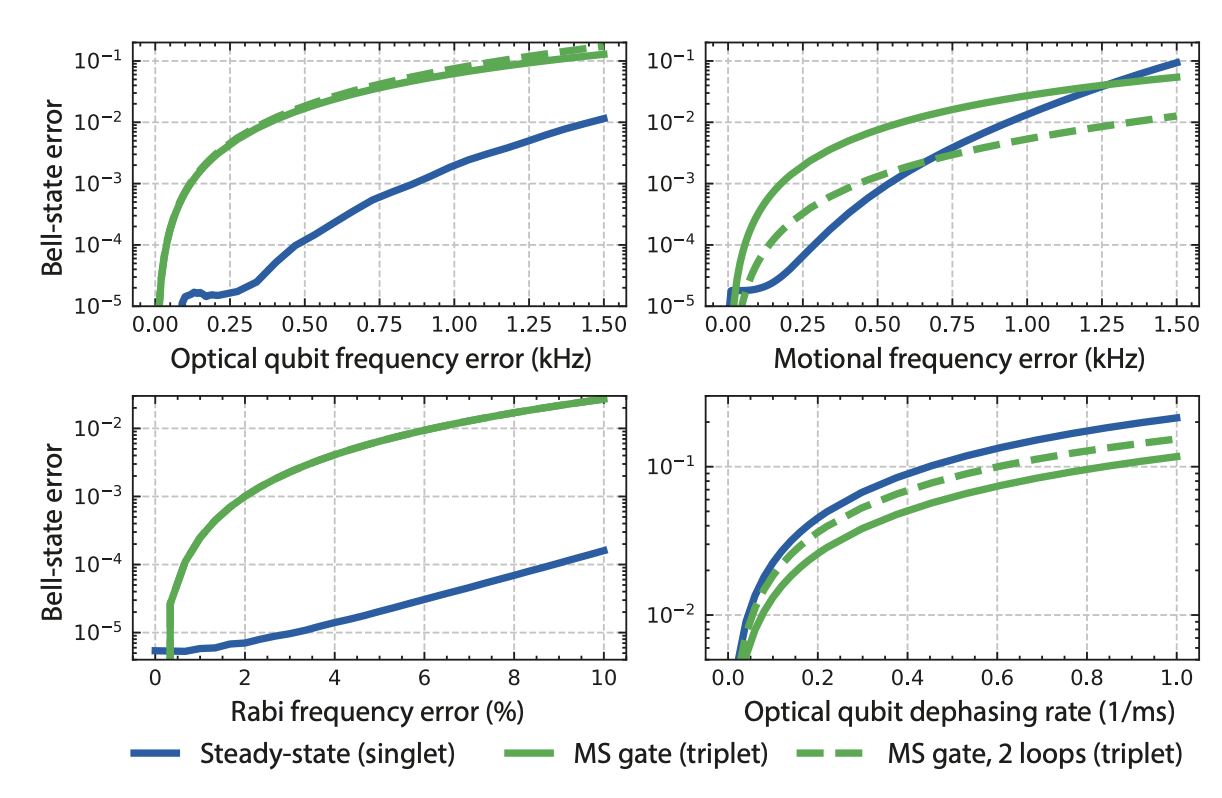
and here is AI result (rounds 1-2 of claim 59)
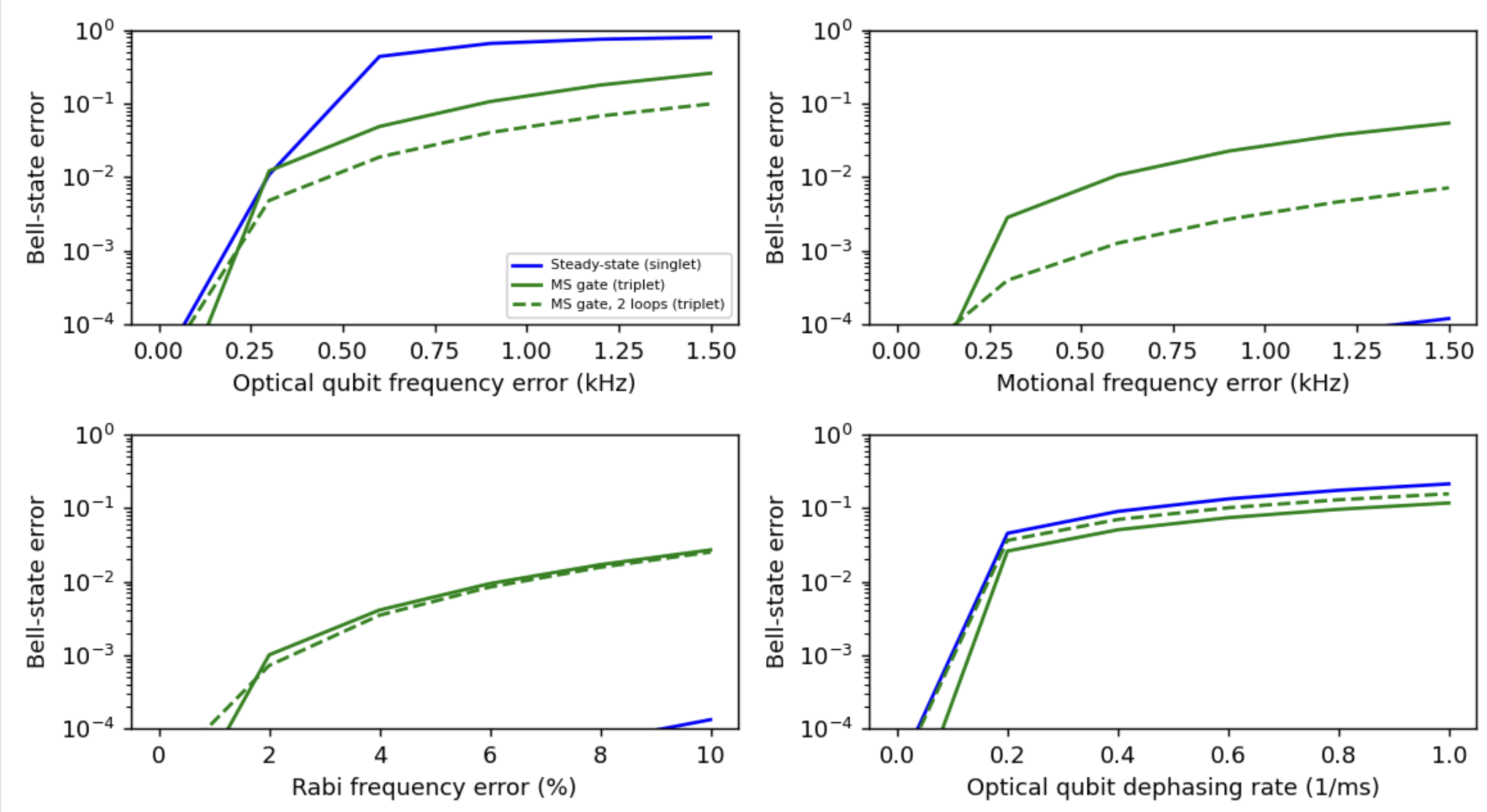
As we can see, AI successfully reproduced the bottom figures, but we have a clear mismatch for the top two figures (the effect of qubit and motional frequency errors). I asked AI to keep working to find the discrepancy.
Within 5 minutes, it found a bug in its analysis of motional errors, and got a better match with one of my figures. Digging in, I found that I had once made the exact same error that AI just did - except I immediately understood that something was suspicious, and worked hard to rectify it.
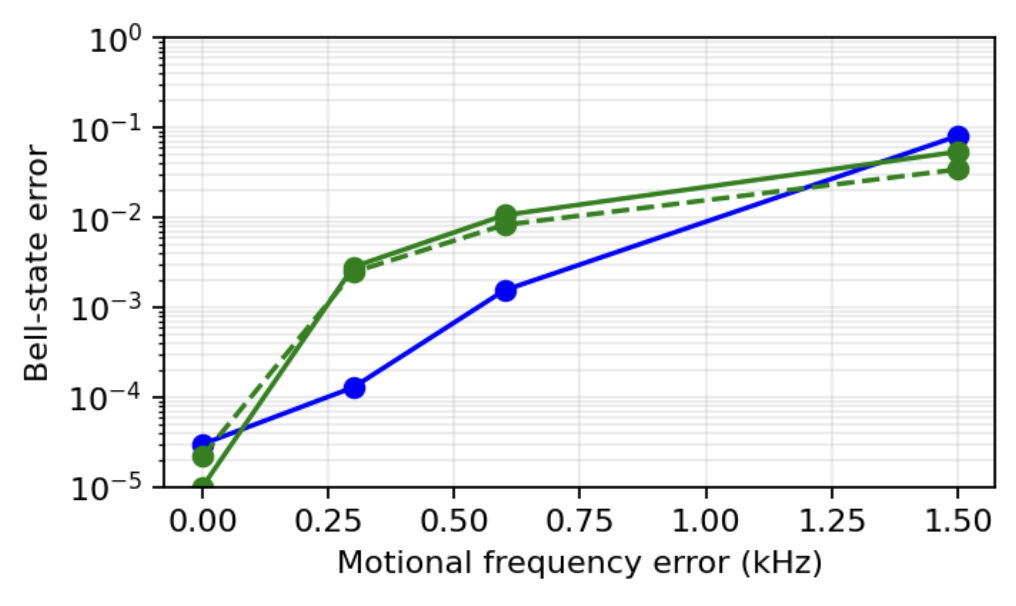
The qubit frequency figure, on the other hand, resisted reproduction. I reviewed the code and immediately became suspicious that AI’s code is not using a large enough motional Hilbert space. Indeed, after I pointed this out, GPT 5.5 performed a convergence analysis to understand how many Fock states it needs, and was able to successfully reproduce the plots.
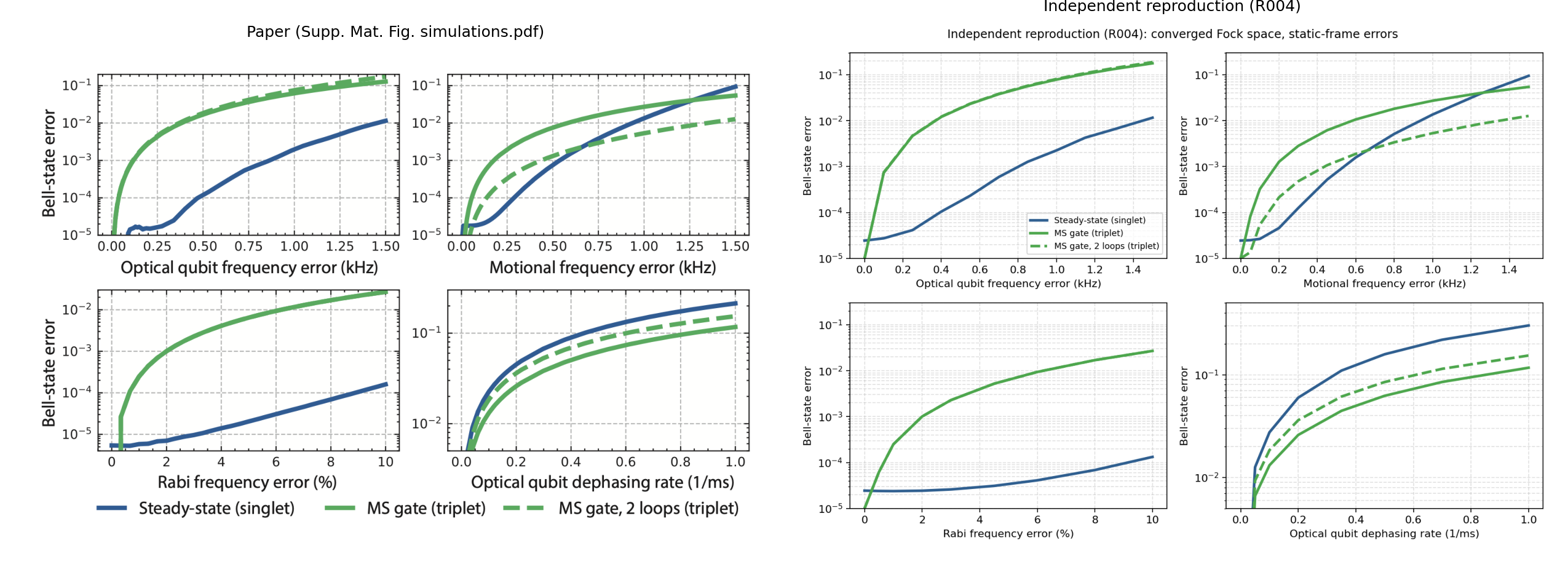
All in all, on this simulation, I score Opus 4.8 and GPT 5.5 as PhD students still getting the hang of things. The analysis they did definitely feels above Master’s level, but a competent, advanced grad student would have likely identified and rectified these errors autonomously.
Notwithstanding, once again, the review as a whole was spectacular, and would have been super helpful to have at the time of writing. Even though AI made some errors, it is really my fault for not including enough details and code in the paper to make it easily reproducible by anyone. Had I been writing the paper today, I would have used this workflow to make sure nobody has to guess how I came to the conclusions I did.
Paper 3, ft. Claude Fable
As I was getting ready to publish this post, Claude Fable became available, and I couldn’t resist the chance to give it a shot. And boy, was I blown away.
First of all, Fable basically made my whole pipeline obsolete. The reason I made the pipeline in the first place is that I found simply asking AI “break this paper into claims and verify each one” produced very poor results, with AI forgetting or bullshitting many verifications. The review pipeline, though cumbersome, enforced structure and accountability, making sure no claim is left behind.
Fable, on the other hand, seems to just follow instructions. Thus, after a single prompt to review arXiv:2606.07736 (a random paper I found that day), I got a full paper reproduction codebase in Python, together with a report that contains:
1) A numerical and/or sympy verification of every numerical and analytical claim


2) Full reproduction of every single figure
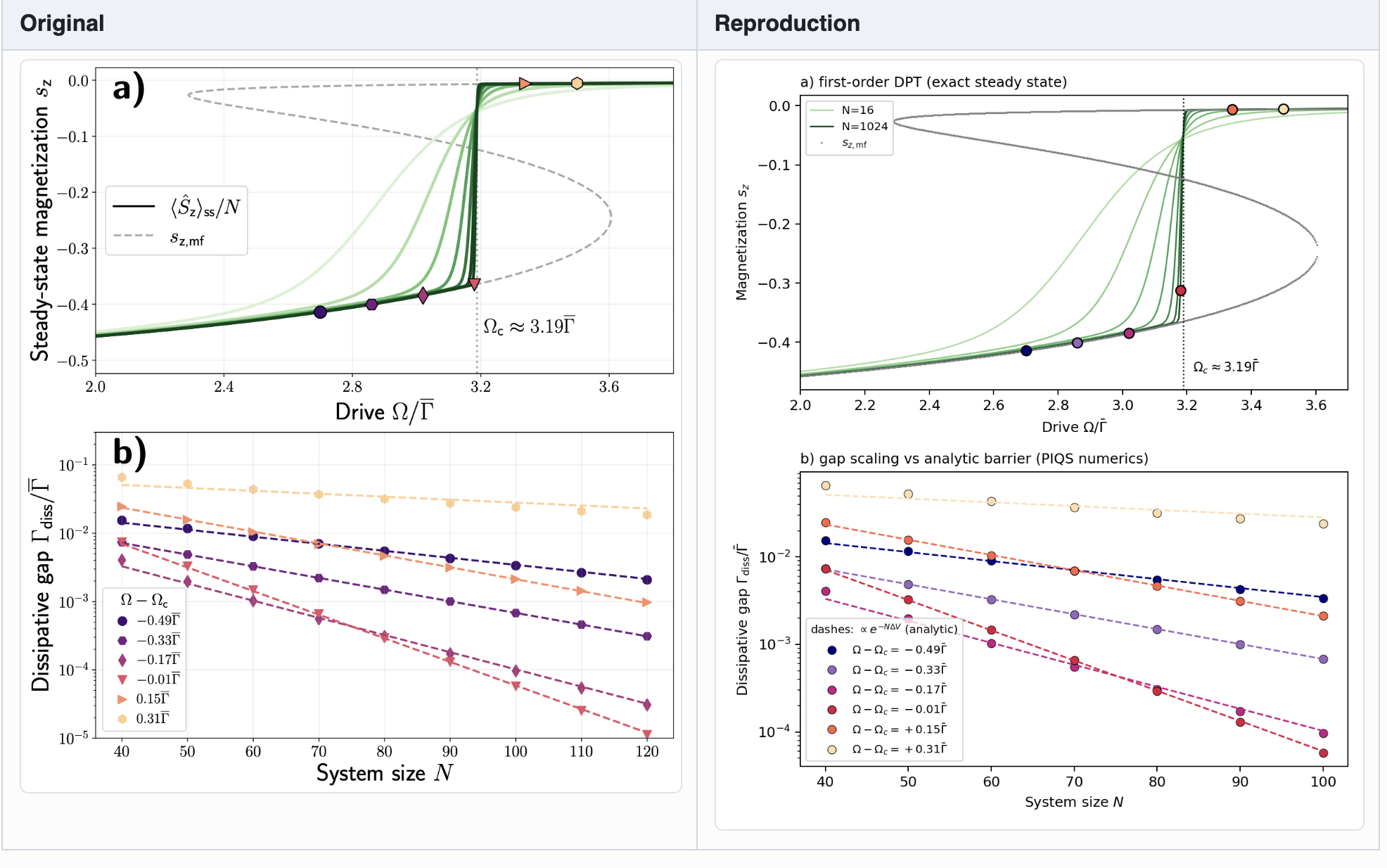
3) A detailed list of errata in equations which, based on a brief review, I think is 100% correct

Oh, and remember how Opus and GPT-5.5 struggled to debug the two plots in Paper 2? Fable managed to reproduce all the results in a single shot.
I’ll be exploring this more in the coming weeks, but for now, it looks to me like Claude Fable is:
- Extremely diligent at long-running tasks, reducing the need for strict drift guardrails from previous models
- Extremely competent at theoretical physics, and capable of spotting BS and subtle issues in the analysis
Summary
Clear take-aways from the experiment:
- The AI tools are fantastic at technical review of physics papers
- Older models need to be encouraged to stay on track; newer models are more capable of completing a full review from a single prompt
- AI can independently reproduce medium-complexity results, somewhere at a level of a PhD student, even when the paper does not provide good guidance on what to do
- AI’s diligence and low cost enable extremely thorough review of minutia that human reviewers usually don’t bother with
- Every paper can be improved through feedback from frontier AI models
I hope that the academic publishing industry will embrace this technology with open arms. Peer review is broken and slow, and AI tools give us a chance to improve quality and throughput. By letting AI focus on the question of “is this paper technically correct”, the humans will have better ability to focus on the most important question of all: “is this paper worth publishing”.