Can AI answer open questions in physics?
The joke is that every time that a new AI model comes out, someone throws it at the Collatz conjecture just in case. It’s actually probably not the worst idea, but “nails high-school physics but cannot yet create the theory of everything” is not the most useful description of the level of physics proficiency of AI models. What I need to know is: as of mid-2026, how good is frontier AI at frontier physics exactly?
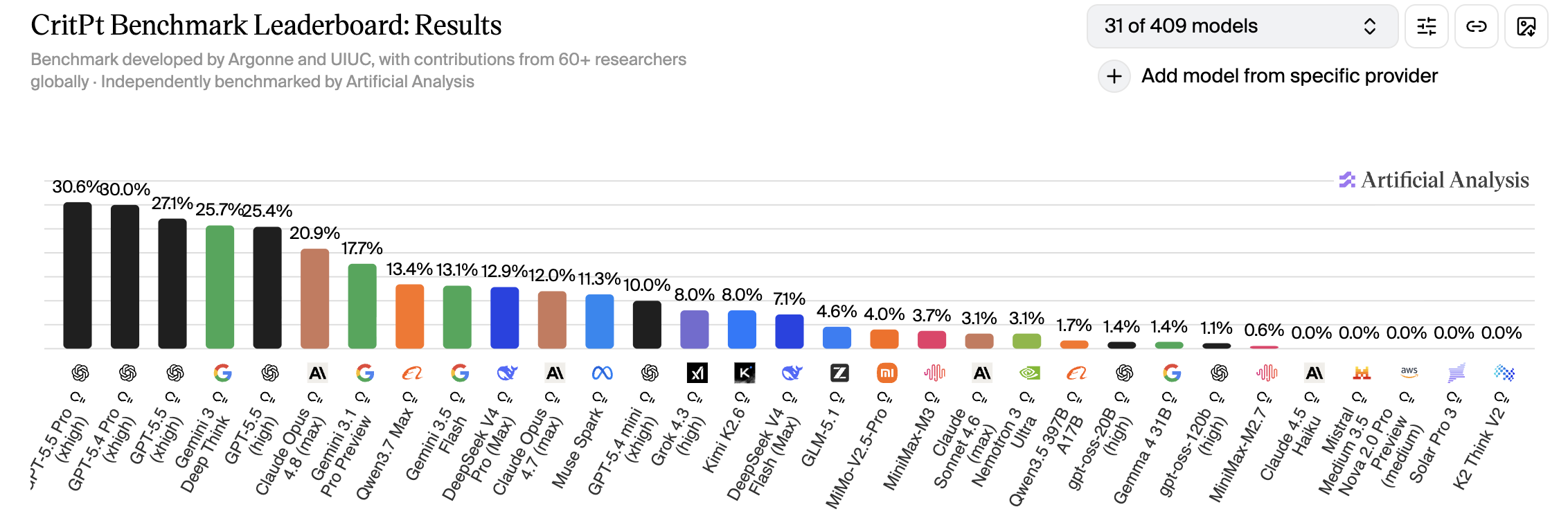
According to the published literature, the answer is “it’s getting there”. For example, CritPt compiled a benchmark of 50 research-level physics questions. At the time of their evaluation in November 2025, the top model scored a mere 12.6%. However, in the nine months since, the top score went up to over 30%, with a total of 10 models scoring better than November’s winner!
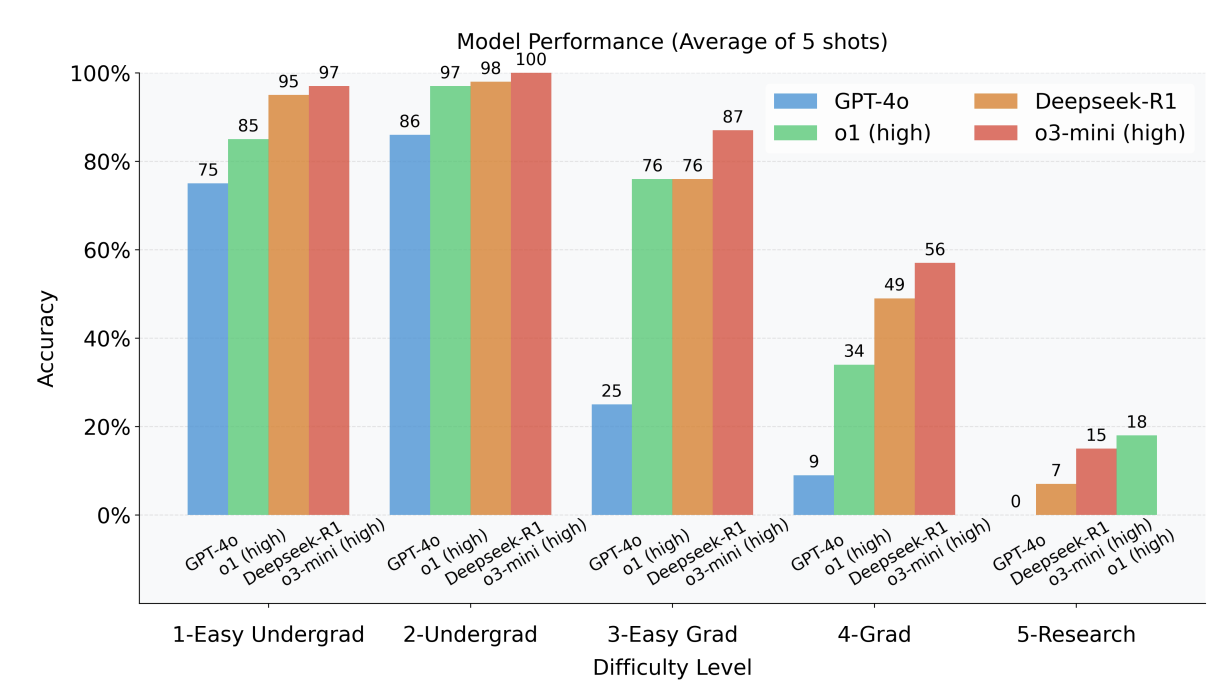
Likewise, consider TPBench, a benchmark for theoretical physics problems. In the preprint published in February 2025, the models pretty much nailed high-school physics, but scored up to ~50% on graduate-level physics and ~15% on research-level physics:
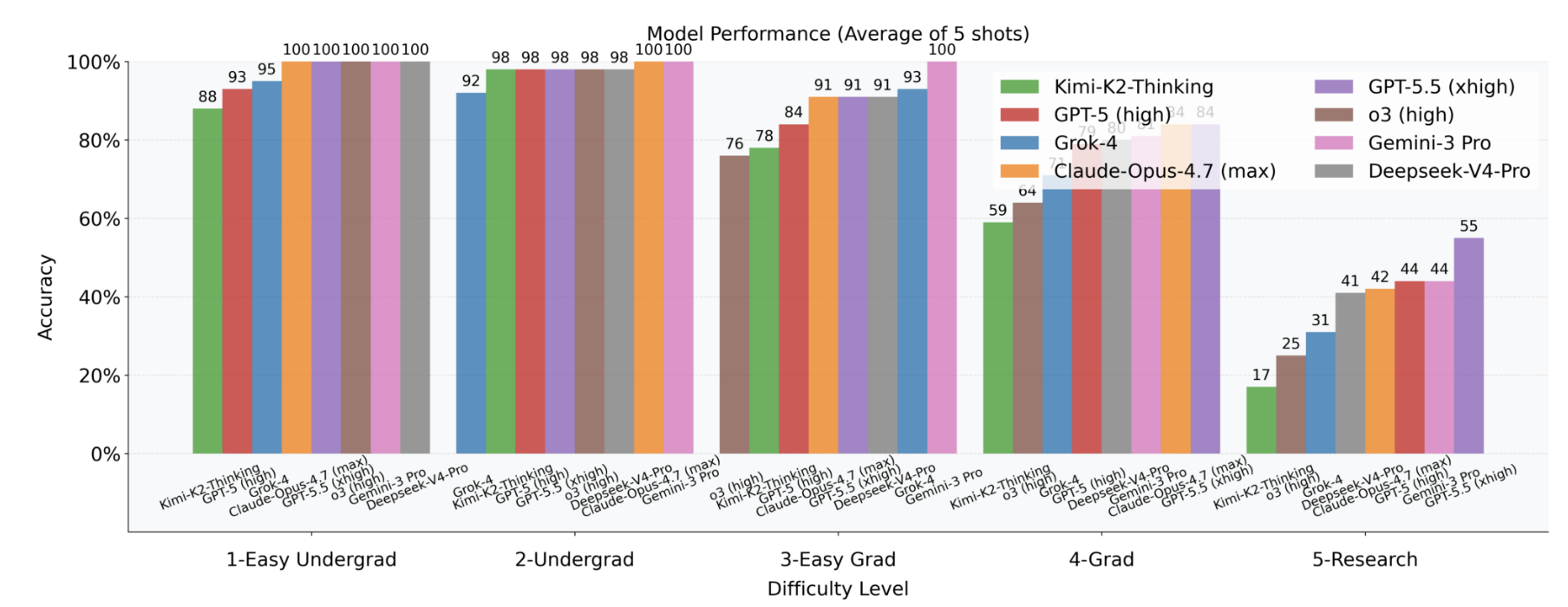
Rerunning the same benchmarks in 2026, the authors found that GPT-5.5 (xhigh) scored ~85% on graduate-level questions and a whopping 55% on research-level questions. That’s pretty astonishing, especially that GPT-5.5 (xhigh) is not even the most powerful physics model out there.
Still, the questions in those benchmarks are generally artificial: they are all concrete, solvable, and someone out there knows the solution. One can also worry that even if the author keeps the answer to themselves, the answer may one way or another “leak” on the internet, e.g. as part of a published research paper.
Thus, a few weeks ago, I decided to make an experiment where I throw frontier AI models at “real” open physics questions. Here is what I found.
What are the open questions in physics?
First clarification - by “open physics questions”, I don’t mean the ones you heard on national geographic, like “what’s the origin of the matter-antimatter asymmetry”!
While we’re all used to hearing about the “big” open questions in physics, the truth of the matter is that the field is full of “small” open questions. In fact, every day physicists around the world publish hundreds of papers and preprints, many of which contain “open questions”. This can be anything from a puzzling experimental observation that eludes explanation, through a lemma that seems reasonable but evades proof, all the way to the long-term proposals for follow-up work.
What’s nice about these open questions is that they’re truly open. Unlike TPBench, answering any of these questions would genuinely advance human knowledge - even if only by a tiny amount and on a very niche topic. Furthermore, unlike existing benchmarks, the question difficulty - or even whether a solution exists - is unknown a priori.
At the same time, I hypothesise that many of them are actually not that hard - a typical “open question” in a physics paper received a relatively small amount of attention from a very small number of humans. This makes them a promising target for AI input.
Scraping open questions
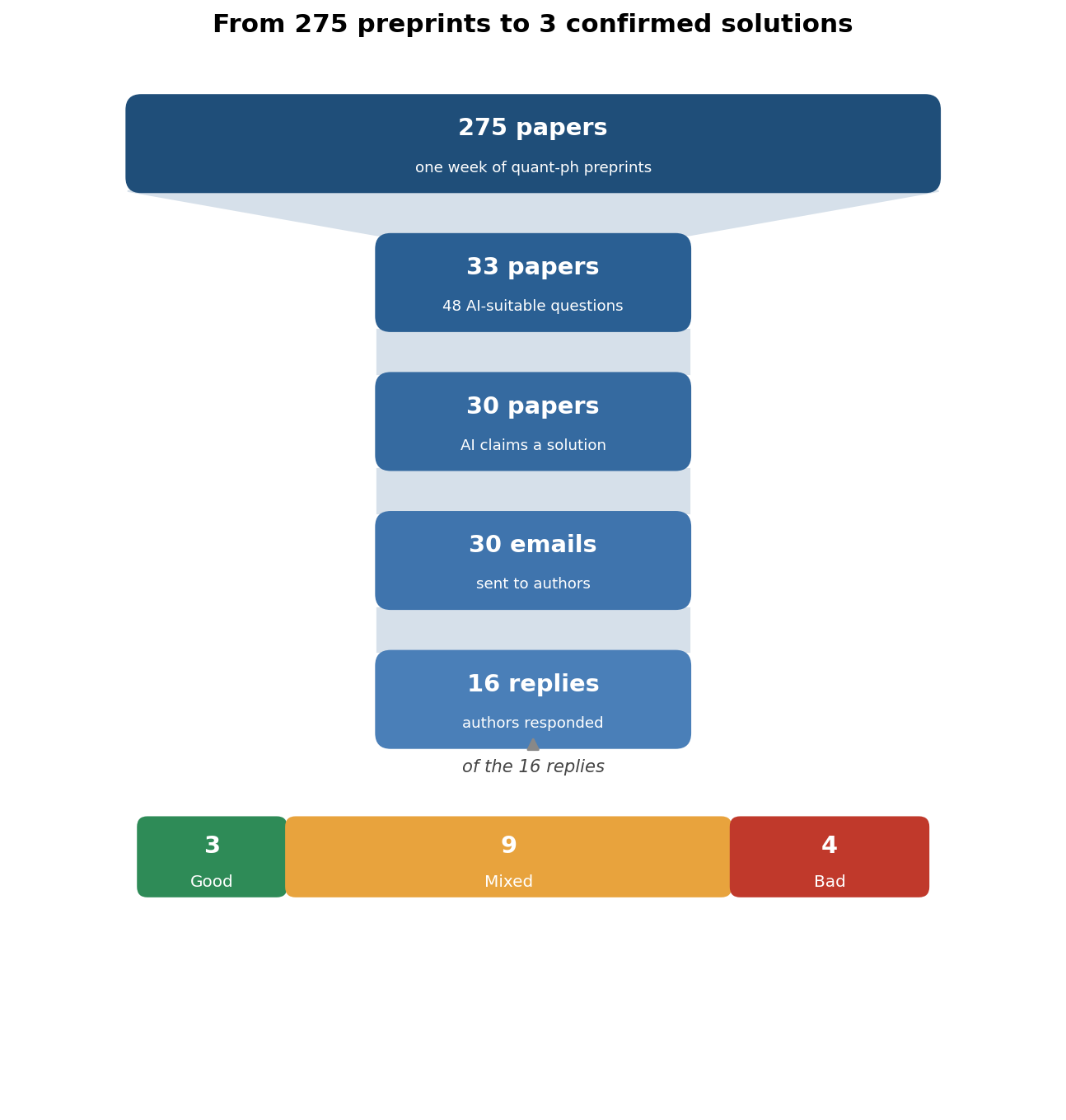
For the experiment, I started by scraping one week’s worth of preprints from the quant-ph arXiv, finding 275 papers with over 200 candidates for open questions based on grepping of phrases such as “open”, “unresolved”, and “future work”.
The first observation was that - unsurprisingly - the vast majority of my “open problems” were (in my opinion) not suitable for AI just yet. Typical reasons were that:
- They’re about experimental / hardware validation. Example from my dataset: “operation at few-kelvin temperatures remains to be demonstrated”.
- They’re vague outlines of future roadmap. Examples: “Future work will explore strong-coupling corrections beyond the Born–Markov approximation, non-Gaussian TLS noise, and machine-learning-based real-time estimation”, “future work on covert quantum communication under realistic uncertainty, including adaptive, correlated, deployment-oriented, and distributionally robust extensions”
- They’re very broad. Example: “The description of the non-equilibrium dynamics of isolated quantum many-body systems […] is a fundamental open question.”
- They’re heavy on practical engineering. Examples: a quantum simulation paper leaves “A full gate-count analysis, circuit synthesis […] and quantum-hardware execution” for future work / another paper asks for “a full end-to-end fault-tolerant distributed-quantum-computing compiler.”
- They’re too big. Example: a paper on high-dimensional layer codes asks about “determining the finite-temperature self-correction properties of these 4D and 5D layer codes.”
- They’re about broad protocol design. Examples: a QKD paper asks about “proving unconditional security for such non-Gaussian-measurement CV-QKD protocol”; a paper on distributed molecular-node quantum computing asks to “design modular architectures and entanglement-generation protocols that achieve fault tolerance with feasible inter-module entanglement rates and hardware-resource requirements.”
I addressed this with a lightweight but aggressive (agentic) down-selection pipeline, aimed to identify questions most suitable for AI assistance. Some personal judgement went into this, but overall, questions received bonus points when they were:
- Yes/no mathematical claims. Example: “does every entangled two-qubit state admitting two pure steered states must have density-matrix rank 2.”
- Questions about formulas or numbers. Example: a paper establishes a threshold formula numerically, and asks for an analytic proof.
- Optimization / characterization questions. Example: a paper asked for “analytically characterizing the maximal possible violation of the realignment criterion over PPT entangled states.”
- Result extension questions. Example: a paper proved a result about single-qubit quantum channels, and asked for extension to multi-qubit channels.
Following this down-selection, 48 questions across 33 papers were extracted and packaged into stand-alone units, and the AI got to work on trying to crack them one by one.
The AI solver
My first attempt used an automated two-agent loop: claude opus 4.8 as the “solver”, and gpt 5.5-xhigh as the “reviewer”. This, however, resulted in a very low success rate. I then switched to gpt 5.5 Pro as the “solver”, with much better success rate. However, as I didn’t have access to that model through an API - only through web UI - the remaining part of the experiment was rather manual and less systematic.
Here is what followed:
- GPT 5.5 proceeded to work on 48 problems across 33 papers
- It claimed to successfully solve 42/48 of them, across 30 papers
- I sent 30 emails to authors of these papers, asking for results verification
- I received a response to 16/30 of these emails
The result of the verification has been:
- 25% (4/16): Bad. AI incorrectly claimed a proof, or misframed the problem
- 55% (9/16): Mixed. AI provided a partial or promising proof, but likely incomplete
- 20% (3/16): Good. AI confirmed to have effectively solved the problem.
Those are the headline numbers, but they hide the really interesting nuance. So let’s dig in into the examples of each, what they tell us about physics, and how to improve the experiment to improve its performance next time.
The bad
One example miss was the problem from Quantum randomness beyond projective measurements. Quote: “a simple question remains open: how much intrinsic randomness can be generated by a given extremal measurement?”. AI claimed to have solved it by reformulating it as a pure-state minimax optimization and doing the variational characterisation. Two problems:
- The paper already did all of this, using a slightly different notation. So in essence, all that AI did was to re-formulate or re-derive some of the results in the paper.
- A human reader would have understood that the real open problem was an explicit solution to the optimisation problem, not just formulating and characterising it
Another misunderstood open question came from The Marginal Problem for Density Operators. In the introduction, the authors made a historical remark that “Leifer & Poulin (2008) left open whether the entropic quantum conditional-independence relation has the full graphoid property”. AI interpreted this question as “does the quantum conditional-independence relation have the full graphoid property for arbitrary density operators“, and was able to quickly find a counterexample.
However, the sentence before started with “In the strictly positive finite-dimensional setting considered here…“. This should have made the AI realise that the actual question was about whether this property holds for strictly positive density operators. This also would have been obvious had the AI read the actual citation of Leifer & Poulin (2008).
The mixed
The largest category, with many different types of partial solutions.
By far the most common author objection is that AI claimed a proof but did not provide enough detail to verify the maths. That was mainly my bad: I have since learned to always prompt the model for detailed step-by-step solutions, with much better results. Still, for this experiment, this led to some inconclusive results, with authors unable to fully verify the claims.
Other than this, the most common situation was along the lines of:
- AI: “I have solved the open problem subject to assumptions ABC, same as the paper”
- Author: “I think it mainly works, but step 10 doesn’t quite follow, step 20 is not fully justified, and assumption C is subtly different from ours “
- AI: “I agree - in fact, I can only prove steps 10 and 20 under additional assumptions DEF”
Thus, in a nutshell, AI provided a partial solution to the open problem, but it would take additional work or human judgement to understand (1) whether the problem is interesting once the additional assumptions are imposed and (2) whether AI really made good partial progress towards the big question, or just followed a dead end.
Selection of other interesting mixed results
In the discussion about a possible solution to an open question from Long-range nonstabilizerness of topologically encoded states from mutual information, the author expressed doubt about whether AI can actually prove the claim, and whether the reduction strategy used in that proof is indeed valid. In a more detailed response, AI admitted the proof is incomplete. However, it was able to show that the reduction strategy is indeed valid. I’ll call it a partial win.
In “Proof of the absence of local conserved quantities in the Holstein model”, authors said “An important direction for future work is to extend our method to other physically relevant fermion–boson coupled systems”. AI saw this, tried the method on a bunch of other physically relevant systems, and declared success, proving that the same trick can be extended from the Holstein model onto “all one-dimensional optical fermion-boson chains with onsite boson-assisted fermion bilinears, including multicomponent Holstein, Holstein-Hubbard, orbital/Jahn-Teller-Hubbard-type chains and flavor-dependent local electron-phonon models.”
The author reply was essentially “sure, but that’s not what we meant by extending our method”. Summarising their view: of course, the method can be directly applied to similar hamiltonians, obtaining similar results - but that’s not necessarily interesting. The interesting physics would come from proving something new about those models using those methods - but as far as they can tell, nothing that the AI did was unexpected or a trivial application.
I give AI partial points here. Even though the authors pushed back, I think it’s possible that what’s a trivial application to authors could have been unexpected to a less expert reader. But I think it really points down to the challenge of actually defining what it means to “solve” a problem in physics.
Another “fuzzy” example came from Statistical Interpretation of the Procedures Measurement of Physical Quantities, which left open a question of whether a certain measurement sequence is possible. AI was able to correctly operationalise the question and prove it’s a logical/mathematical possibility. However, the author pointed out that the truly interesting question is whether the measurement admits an actual experimental realisation. Again - actually crisply formulating the open question is often half the work!
A fun final example of a “mixed” result was from Symmetric dilations of Pauli channels and semigroups, which solved a single-qubit case, and concluded with “Future work may extend our results to the construction of physical dilations of multi-qubit Pauli channel”. AI attacked this problem head on, and was able to derive some results, albeit under more stringent assumptions. The author commented that he hadn’t actually intended to ever tackle this specific problem, but now that AI took the first steps, he might actually give it a go :)
The good
Some clear winners:
The paper One pure steered state implies Einstein-Podolsky-Rosen steering asked whether every entangled two-qubit state admitting exactly two pure steered states must have rank 2. AI confirmed it with a kernel-dimension proof, and authors confirmed the AI assessment.
The paper An Exponential Sample-Complexity Advantage for Coherent Quantum Inference proposed a randomized-purification-then-cloning channel, and left open if the channel is optimal when producing more outputs than inputs. AI produced a counterexample showing the proposed channel is not optimal in a small case, because the loss traces out purifying registers and a system-only cloner can do better. Authors confirmed the solution, although noted the win is small, because it’s unclear if the conjecture can be repaired in light of this counterexample, or whether the counterexample is genuinely important.
Finally, the paper “The relative entropy of magic and its nonadditivity” contained one open question, and one edge case in the proof. AI was able to address them both, and the authors will include the results in the upcoming revision.
What I learned
At the start of this experiment, I set myself a goal of genuinely answering one open physics question. The resulting hit rate of ~20% has been very impressive, especially considering that the AI is single-shotting the problem with no expert guidance. Thus, I say the experiment is a win for the AI physicist.
But as far as I’m concerned, the experiment is just beginning
Prompt and pipeline improvements
Despite the moderate success of v0.1 above, I think one can do significantly better with only slightly better prompting and workflows. Based on the shortcomings of the first attempt, I noted the following prompts for attempt v0.2:
Do not claim an open question is solved until you have:
- Quoted the exact open-question text and interpreted it in context.
- Scanned the rest of the paper for where the apparent question is already answered, formalized, specialized, or partially resolved. If the paper already gives a variational principle, SDP, optimization, theorem, reduction, example, or supplement-level answer, do not present that as the solution. Identify what remains unresolved after the paper’s own answer.
- Distinguished explicit solution, constructive method, implicit reformulation, numerical evidence, and heuristic. A reformulation or finite-but-intractable expression is not a solution unless the authors explicitly asked only for that.
- Checked whether you are solving the intended question rather than a weaker, special, easier, or already-known version.
- Written every hard proof step explicitly, with no “it follows” gaps. For each nontrivial step, provide either a derivation, a cited theorem with hypotheses checked, or mark it as unproven.
- Provided reproducible code, inputs, outputs, and independently checkable certificates for computational or enumeration-based claims.
- Tested the proposed solution against examples, boundary cases, low-dimensional cases, and known cases mentioned in the paper.
- Checked whether the result is already known, obvious to experts, or a routine extension of existing arguments. State novelty separately from correctness.
- Stated all modeling choices and verified that they match the paper’s definitions. If multiple resource notions or interpretations exist, say which one is being solved.
- Separated correctness, completeness, tractability, and significance. A correct lemma, benchmark, or promising construction is not automatically a solved open problem.
- Run a final self-audit: for every claim an author might challenge, either give a step-by-step derivation or downgrade the claim to conjectural, partial, or incomplete.
Use “solved” only if all checks pass. Otherwise label the result as partial, proposed, plausible, or off-target, and state the exact remaining gap.
I also need to set this process up as a fully autonomous multi-agent loop. The manual intervention I had to make to circumvent the lack of API for gpt pro was manageable for the proof of concept, but too annoying in the long run.
One approach I briefly considered but rejected was to waterproof the maths through auto-formalisation in Lean. I still think this is an overkill, but the continuous stream of progress in this area sometimes gives me pause. Perhaps in not-too-distant future, this experiment can be done in a way where all mathematical statements are “guaranteed true” and require no manual verification, leaving us to focus on physics only?
The nuances of open questions in physics
Turns out that formulating and evaluating open questions in physics is a subtle art. While a small minority of questions are concrete, crisp and “AI-ready”, most of the time, open questions tend to be extremely fuzzy and vague. Examples include:
- “Is this method practical?”
- “What’s the physical interpretation of this equation?”
- “Can theoretical advantage of this protocol turn into practical gains?”
Furthermore, a lot of the time, it is really unclear or even unknowable ahead of time what exactly constitutes a solution. For example, when we say “it is an open question whether method A can be applied to system X”, what do we mean exactly? Do we mean that it is mathematically applicable? Or that it can be done in practice? Or that applying it produces valuable insights? Or something else entirely?
Likewise, it is often unclear what level of mathematical description is appropriate for which question. In some cases, implicit results suffice; in others, exact analytical solutions are necessary. In some domains, establishing a result numerically is sufficient for all intents and purposes, while in others, rigorous mathematical proof is necessary. What’s needed is highly contextual, and also involves trial-and-error.
Note I’m not saying this as a criticism. Part of the beauty and the art of physics is that it’s not quite exact, formal, and concrete. As Einstein said, “if we knew what we were doing, it wouldn’t be called science”. The fuzziness of physics is often a feature, not a bug.
Finally, for better or worse, most physicists don’t put very much effort into formulating the open questions - probably because they don’t expect anyone to actually pick up the challenge. Thus, “open questions” are often effectively “notes to self” - or “notes to the editor” as it’s bad form to finish a paper without an outlook. As long as that persists, we can expect some miscommunications with AI agents who love to take us on our word!
Let’s follow this up?
I think this style of AI benchmarking is really unique and insightful, and is ready for a larger-scale test. Because physicists seem to be very open to engaging and reviewing AI work in surprising detail, a more careful study should be able to extract much more information about real-world applicability and limitations of AI models - not to mention more statistics.
Also: there is potentially only a short window of time that this experiment can actually be run. This is because today, most physicists don’t use AI in this way - and those that do do not use the frontier maths models like gpt-5.5 pro (trust me, I asked). So if we want to understand exactly how much value frontier models bring to the table, we have to ask now, while the table is mostly filled with human physicists!
If you’re interested in collaborating on this, or if you’d like to sponsor this token-hungry work, let me know. Should be fun!